Rathorian
Rathorian Est-ce que tu as fait une mise à jour du serveur pour qu'il reboot ?
Je n'ai fait aucune mise à jour du serveur pour qu'il reboot, à la base est devenue injoignable sur les ping de monitoring réseau de OVH du coup OVH m'a envoyé un mail pour me prévenir qu'un technicien allait intervenir sur le serveur pour qu'il recommunique à nouveau.
S'en est suivi leur modification étrange en forçant un reboot de la machine alors qu'aprés inspection des logs la machine n'avait plus le réseau mais continuait de tourner normalement et elle même n'arrivait plus à communiquer vers l'extérieur.
Lorsque j'ai reçu le mail de résolution la raison qui a fait que le reboot n'a pas fonctionné était la suivante "duplicate md2"
Aprés inspection dans le mdadm.conf il y avait 2 lignes de configurations pour md2 effectivement et cela doit être clairement dû à une faute de ma part.
Mais je ne vois pas en quoi cette erreur a forcé le technicien d'OVH à déplacer la partition de boot sur un de mes HDDs qui était en RAID 10 et qu'il me bascule du coup les 2 autres HDDs en raid0 ... il suffisait de commenter la deuxième ligne md2 dans le mdadm.conf pour corriger le soucis de boot ...
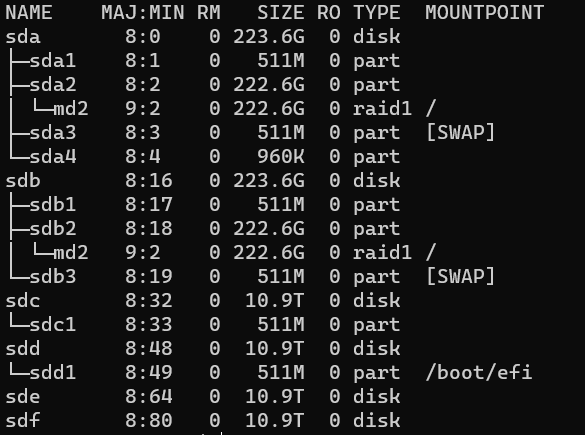
Rathorian Ta partiton de boot avait été créer à quel endroit à l'installation ? en EFI ?
Elle avait été créé en efi sur sda1 d'ailleurs en remontant sda1 je vois bien exactement les mêmes fichiers que sur sdd1
Par ailleurs chose intéressante lorsque je compare le résultat des 2 commandes suivantes :
root@debian:~$ mdadm --examine /dev/sdf
/dev/sdf:
Magic : a92b4efc
Version : 1.2
Feature Map : 0x1
Array UUID : c681059e:c6d5c4ad:5574e20f:22585e87
Name : debian.example.com:3 (local to host debian.example.com)
Creation Time : Sun Dec 8 02:22:32 2019
Raid Level : raid10
Raid Devices : 4
Avail Dev Size : 23437506560 (11175.87 GiB 12000.00 GB)
Array Size : 23437506560 (22351.75 GiB 24000.01 GB)
Data Offset : 264192 sectors
Super Offset : 8 sectors
Unused Space : before=264080 sectors, after=0 sectors
State : clean
Device UUID : ffdeb712:8226a27b:ad4083c6:bd127989
Internal Bitmap : 8 sectors from superblock
Update Time : Sat Jul 31 02:18:29 2021
Bad Block Log : 512 entries available at offset 96 sectors
Checksum : e8f1308f - correct
Events : 292680
Layout : near=2
Chunk Size : 512K
Device Role : Active device 3
Array State : AAAA ('A' == active, '.' == missing, 'R' == replacing)
et
root@debian:~$ mdadm -D /dev/md3
/dev/md3:
Version : 1.2
Raid Level : raid0
Total Devices : 2
Persistence : Superblock is persistent
State : inactive
Working Devices : 2
Name : debian.example.com:3 (local to host debian.example.com)
UUID : c681059e:c6d5c4ad:5574e20f:22585e87
Events : 292680
Number Major Minor RaidDevice
- 8 64 - /dev/sde
- 8 80 - /dev/sdf
On voit que la première commande montre que /dev/sdf fait parti d'un raid10 composé de 4 HDDs ce que j'avais avant donc ok nickel sauf qu'ensuite la deuxième commande montre que l'array de mon RAID 10 est en fait un RAID0 composé que de 2 HDDs (alors que les 2 ont bien le même Array UUID !!
Et enfin cerise sur la gâteau on peut voir que le RAID10 a un dernier Update Time à 02h18 et devinez quoi, la panne commence à 02h28 et se finit à 03h19 et là mon RAID10 s'est transformé en RAID0.
J'ai l'impression que quoiqu'il arrive mes données seront pas récupérables, j'ai fait un ticket à OVH pour leur demander des explications et leur demander un dédommagement mais si vous pensez qu'il y a un moyen de récupérer mes données même si ce n'est qu'en partie de quelques façons que ce soit je suis preneur !
Je me dis que peut être qu'en supprimant le raid0 et en demandant à mdadm de recréer le raid10 je pourrai récupérer mes données quasi intacte vu qu'aprés tout une seule partition de 500Mo sur chacun de mes 2 premiers disques a été créé donc je me dis que le reste des données doit toujours se trouver là.
Mais j'ai peur de faire une fausse manip qui ferait que je les perde à jamais, donc si vous avez des idées je suis preneur !