Hello 👋,
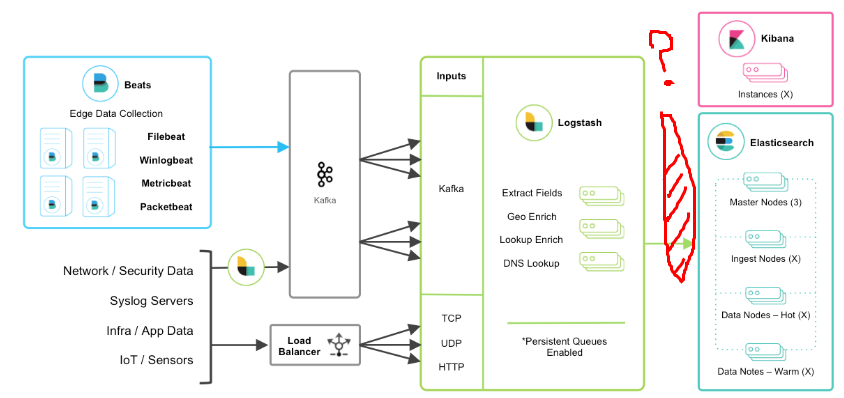
Je dois mettre en place une infrastructure capable de logguer 1 milliard de requêtes HTTP par jour (Ca represente environ 1TB de donnée), en conservant ces données pendant 3 jours.
Pendant cette période, je dois les agréger selon certaines dimensions comme le domain, device ou le pays de l'IP.
Je pensais à utiliser ElasticSearch pour les logs puis Postgre pour les data aggrégés.
Cependant, je ne suis pas sûr qu'Elastic soit conçu pour gérer cette quantitée de données et s'il n'existe pas de meilleures solutions qui consommeraient peut être moins et seraient donc moins couteuses...
De plus, je ne sais pas exactement quelle est la meilleure solution pour envoyer ces logs à Elastic ou à une autre solution. Je ne pense pas qu'envoyer chaque requête HTTP à log par API a elastic soit la meilleure solution de procéder. Pensez-vous qu'il soit préférable d'enregistrer les logs dans un fichier et d'envoyer les fichiers périodiquement au système de logs (Peut etre logstash pour ca) ?
Merci beaucoup pour votre aide !